<< ..
Airflow动态生成task
1. 问题是什么?
数据采集日常调度任务中,通过Airflow的SSH算子远程执行脚本,将PostgreSQL导入到Hive中。导入的单元为库级别的粒度。
库级别粒度导入带来的问题是,当库内的某个表出现问题,任务需要回滚,回滚的无法做到单个表级别,只能全库回滚。 库级别导入的做法为运维带来不必要的成本。
本次调研是希望通过一定方式,将导入粒度缩放到表级别粒度,以期做到精准控制导入失败的情况。
2. 方法是什么?
2.1 整体架构
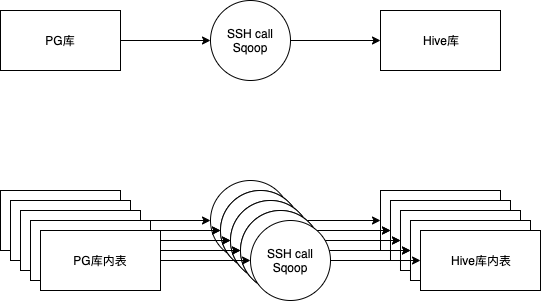
抽象形式如上图所示,基本架构组合分为三个部分:输入源是PG,导入工具是Sqoop,输出到Hive中。
预想的方法是,将PG库内的表读出,作为单个子任务输入,维持原架构组合不变情况下,为每个表创建导入task。
2.2 输入环节
检索关键字airflow 动态生成 task得出结果均不符合预想方法。重新分析需求,可以先从原PG库导入配置文件入手。
PG库导入配置文件基本形式如下,是一个以|为分隔符的文本文件:
PG库名|PG表|HIVE库名|HIVE表名|HIVE的HDFS路径|导入模式|MR数|用于分割的字段|增量模式使用的列|时间
针对配置文件,构建函数用于读取配置信息:
def load_table_list(table_file=TABLE_FILE, **kwargs):
table_list = []
with open(table_file) as csv_file:
csv_reader = csv.reader(csv_file, delimiter='|')
for row in csv_reader:
table_mapping_info = {"pg_db": row[0] or '@',
"pg_table": row[1] or '@',
"hive_db": row[2] or '@',
"hive_table": row[3] or '@',
"target_dir": row[4] or '@',
"import_mode": row[5] or '@',
"mr_num": row[6] or '@',
"split_key": row[7] or '@',
"check_column": row[8] or '@',
"day": row[9] or '@'}
table_list.append(table_mapping_info)
return table_list
2.3 动态生成task
函数load_table_list将用于把库级别的配置文件转换为一个包含各个表信息的list。遍历list内各个元素,就是表级别粒度信息。后续将表级别信息传入原SSH call Sqoop环节,便可以构建出各个表的task:
for table in load_table_list(table_file=TABLE_FILE):
start >> multitasking_jobs(table, dag) >> complete
这里特别用到了start和complete两个task,其主要作用是负责开头和收尾的占位。
2.4 远程调用
上段代码中的multitasking_jobs便是负责SSH算子的环节,在该环节内调度远程的sqoop脚本,输入是table级别的信息:
def multitasking_jobs(table, dag, **kwargs):
task_name = str(table['hive_db']) + "_" + str(table['hive_table'])
return SSHOperator(
ssh_conn_id='ssh_21',
task_id="import_{}_table_into_hive".format(task_name),
command='/bin/bash /home/master/airflow_etl/pg_2_hive/import_pg_2_hive.sh ' + " ".join(list(table.values())),
dag=dag)
2.5 完整示例
完整示例如下:
import csv
import logging
import airflow
from airflow.models import DAG
from airflow.utils import dates as date
from datetime import timedelta, datetime
from airflow.utils.decorators import apply_defaults
from airflow.operators.sensors import ExternalTaskSensor
from airflow.operators.dummy_operator import DummyOperator
from airflow.operators.python_operator import PythonOperator
from airflow.contrib.operators.ssh_operator import SSHOperator
DB_NAME = "name_of_your_db"
TABLE_FILE_PATH = "/usr/local/airflow/dags/"
TABLE_FILE = TABLE_FILE_PATH + DB_NAME + ".txt"
def multitasking_jobs(table, dag, **kwargs):
task_name = str(table['hive_db']) + "_" + str(table['hive_table'])
return SSHOperator(
ssh_conn_id='ssh_21',
task_id="import_{}_table_into_hive".format(task_name),
command='/bin/bash /home/master/airflow_etl/pg_2_hive/import_pg_2_hive.sh ' + " ".join(list(table.values())),
dag=dag)
def load_table_list(table_file=TABLE_FILE, **kwargs):
table_list = []
with open(table_file) as csv_file:
csv_reader = csv.reader(csv_file, delimiter='|')
for row in csv_reader:
table_mapping_info = {"pg_db": row[0] or '@',
"pg_table": row[1] or '@',
"hive_db": row[2] or '@',
"hive_table": row[3] or '@',
"target_dir": row[4] or '@',
"import_mode": row[5] or '@',
"mr_num": row[6] or '@',
"split_key": row[7] or '@',
"check_column": row[8] or '@',
"day": row[9] or '@'}
table_list.append(table_mapping_info)
return table_list
def pg_robb_stark_2_hive(parent_dag_name, child_dag_name, args, schedule_interval):
dag = DAG('%s.%s' % (parent_dag_name, child_dag_name),
default_args=args,
schedule_interval=schedule_interval)
# 牵头占位需要,检查表配置文件是否可用
start = DummyOperator(
task_id="task_start",
dag=dag)
# 收尾占位需要
complete = DummyOperator(
task_id="complete",
dag=dag)
end = DummyOperator(
task_id="task_end",
dag=dag)
# 动态生成连接关系
for table in load_table_list(table_file=TABLE_FILE):
start >> multitasking_jobs(table, dag) >> complete
# 连接头尾
dag >> start
complete >> end
return dag
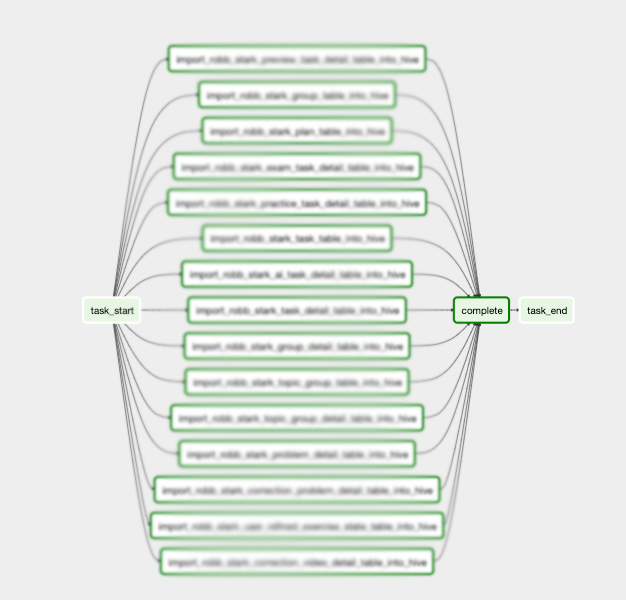
最终效果如下:
3. 缺陷是什么?
测试的Airflow版本为1.9.0。基于上述方法动态生成task的缺陷集中在维护和侵入两个方面,主要是三点:
- 缺陷一,需要在
airflow的dags目录内维护管理数据库表的文件。库表的信息默认从dags中加载。 - 缺陷二,远端ssh调度的shell脚本传入值形式会和原传入值不一样,需要侵入原项目中做针对输入的修改。
- 缺陷三,动态生成的task任务均来自于配置文件,当配置文件改变以后,要手动在Airflow Web页内刷新任务。