阿里云 E-MapReduce
本文书摘于阿里云官方文档抽取核心信息备忘。
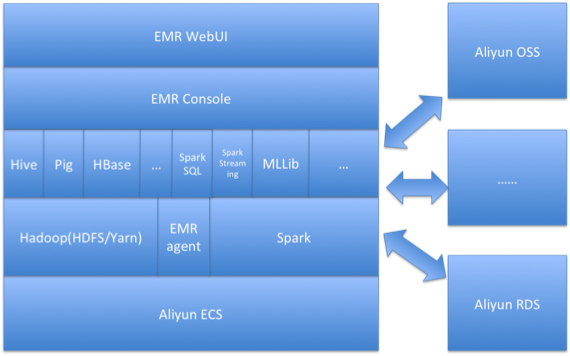
E-MapReduce是运行在阿里云平台上的一种大数据处理系统解决方案。它能够让用户将Apache Hadoop和Apache Spark运行在阿里云的云平台上,提供给用户在云上的分析和处理大数据的平台。通过将Hadoop和Spark运行在云平台上,让用户可以非常方便的使用Hadoop和Spark生态系统中的其他周边系统(如Apache Hive,Apache Pig,HBase等)来分析和处理自己的数据。不仅如此,用户还可以通过E-MapReduce将数据非常方便的导入和导出到阿里云其他的云数据存储系统和数据库系统(如Aliyun OSS, Aliyun RDS)中。
如果不借助云服务的情况下,我们通常需要经历:
1,评估业务特点 -> 2,选择机器类型 -> 3,采购机器 -> 4,准备硬件环境 -> 5,安装操作系统 -> 6,部署Hadoop和Spark等app -> 7,启动集群 -> 8,编写应用程序 -> 9,运行作业 -> 10,获取数据等一系列的步骤
这些流程中,其实真正跟用户的应用逻辑相关的是从第8步才开始,前面的各项工作都是前期的准备工作。而通常这个前期工作都非常冗长繁琐。企业想涉足大数据,真的还要耗费巨资搭建一个机房不成?
Aliyun E-MapReduce是构建在阿里云主机( AliyunECS )上,基于开源Hadoop,Spark及其ecosystem(Hive,Pig,HBase等),提供大数据计算,处理和分析的云产品。它是提供了从主机选型,环境部署,集群搭建,配置,运行,作业配置,作业运行,集群管理,性能监控等一系列的集群管理工具的集成解决方案。通过使用Aliyun E-MapReduce,用户可以从繁琐的集群构建的各种采购,准备,运维工作中解放出来,只需要关心自己的应用程序的处理逻辑。不仅如此,Aliyun E-MapReduce还提供给用户非常灵活的搭配组合方式,用户可以根据自己的业务特点选择不同的集群服务。比如,用户的需求是对数据进行日常的统计和简单的批量运算,可以只选择在E-MapReduce中运行Hadoop服务;而如果还需要有流式计算和实时化相关的需求,可以在Hadoop服务基础上再加入Spark服务。
目前缺陷? 尚未支持类strom毫秒级别的响应,但提供了Spark-streaming。