关于数据链路的任务调度
我是一名数据研发工程师,不同于前端后端工程师那样有明确的分工和完整的协作方法论,作为一名数据开发工作负责的部分涉及到数据链路的各个环节。 由于各个企业涉及的数据问题不同,数据开发的职责也存在很模糊的定位,好像跟数据擦边的都能叫数据开发,但是具体分工和职责又确实千差万别。 我不知道你是否经常熬夜处理问题,如果是的话,这是一篇讨论夜间任务调度的博客,希望你能从文中体会到感同身受之处。同时,本文也是我对自己、对这项工作的一个阶段性总结。
关于最开始
从我最开始的工作讲起来,其实也非常简单,那就是把线上的数据搬运到线下来。
用到的技术也非常简单,就是部署一个crontab任务。
这个crontab任务里需要调一个shell脚本,脚本负责数据的下载、压缩、传输、回滚。
完成整个数据搬运的工作流后,剩下的工作就是基于线下的数据开始分析。
那时候公司业务不过是刚刚起步,没有太过复杂的数据场景,于是就是python脚本写一堆查询去出最简单的PV、UV。
即便是如此简单的场景,依然遇到很多问题。
首先就是crontab时间差战争,线上任务凌晨1点开始执行,我们预期凌晨3点结束。
那就是想当然的把线下拉取数据的脚本启动时间设置到凌晨5点开始。
随着数据量不断上涨,线上任务直接执行到了凌晨6点。
第二天一早发现,线下任务启动失败。
还需要设计可容错的shell脚本,我花了很长时间一次次重构线上线下两段脚本,最终将脚本设计成模块化的,有点面向对象意思的脚本。
这样就可以在脚本执行出错的时候,手动的修改模块,注释掉已经执行成功的部分,缩短任务重试时间。
对crontab + shell任务的执行状态是不可控不可预期不能精准处理失败的。即便是最优化的脚本,依然还是会遇到很多问题。比如cron进程被误杀,比如网络中断。
每天早晨醒来,第一件事就是看看任务是否执行成功。
为了失败任务尽快回滚,极端情况下,我在夜间各个时间段设置了闹铃,在代码各处设置了邮件报警。
即便是从线下SSH Callback到线上,也经常发生因为ssh长时间链接导致网络中断的问题。
让数据及时交付这件事,明明这么简单,我就杠上了。
关于探索期
随着企业业务发展,数据量增长是一个方面,另一个方面就是业务开始负责,你作为一个“数据工程师”要与不同的业务方不同的业务库打交道。
最开始的crontab开始显得难以应付,线性流程的数据调度,时间和空间维度都不再合适。于是开启了大数据之路。
什么是大数据,什么是大数据工程师,内心充满疑惑。技术栈拓展,似乎触碰到了数据最主流。
后来我才逐渐清醒,处理海量数据,不一定非要上Hadoop,大数据重要的是思想,处理数据的方法论。
当然,就算是大数据也得先解决数据任务调度问题,这个时候最著名的两个选择就是Azkaban和Oozie。
我们最后的选型是用Oozie,更多原因是我们的数据处理平台使用的是HDP。
也就是在这个时候,我终于清楚的知道这件事有个很官方的命名Workflow Scheduler。
而相应工具一般被称为Workflow Management Systems。
疲于应付cron的不直观难控制,Oozie似乎成为了我的睡眠救星。 终于可以不再担心时间差了。
事实上,更复杂的处理场景才刚刚开始。 业务多了,就代表有多个Oozie任务需要部署。 但是从数仓建设角度将,这些任务又不可能完全独立分散。
痛点来了,Oozie不能清晰的表述出各个任务的依赖关系。 处理不好依赖关系,依然无法又好又快又安全的交付最终数据。
回到当下
终究是业务推动架构演化。复杂调度依赖的场景下,机缘巧合遇到Airflow,粗一看Apache Airflow的特性命中痛点。
你可能会搜到一堆Airflow特性,但是说白了选择使用这款工具的根本原因还不是馋人家Web UI吗?
人间首款开源的好用的可视化依赖关系图,用到就爽到。 依赖关系终于清晰了! 失败重试、小面积崩溃不影响主线,用的好就赚到。
Airflow从架构上也很好的解决了任务管理和自身鲁棒性:
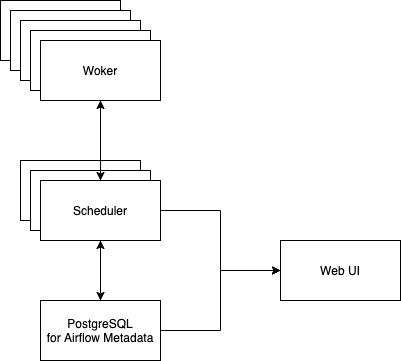
最底层数据库负责存储各个任务元数据,以及任务状态。
数据持久层之上是统一的Scheduler调度模块,这部分可以做到多节点启动,防止因为单点故障导致Airflow停摆。
Scheduler会控制任务
Worker就是执行任务的具体进程。由Scheduler统一调度管理这些Worker的具体状态。其技术本质是Celery。
我觉得理解好Airflow的整体架构,可以套用到其它分布式处理系统上去。
Web UI是Airflow的惊艳之处,底层系统的信息完美的反应到前端中,对DAG的图化展示可以让使用者清晰了解任务依赖关系,以及对每个task的状态反映和控制,都可以通过Web界面下操作完成。
在实际的生产环境使用上,我们大胆的使用了docker-compose做容器编排,将Airflow系统涉及的多个组件容器化管理。
这里对应有功能上的取舍,考虑到未来发展不可控,不能完全被一项技术绑死,全部调度任务均使用SSH Operator在容器内基于ssh远程调用。
不过调度系统使用依然没有完全银弹,在Airfow生产环境实践过程中,依然遇到重重困难。 印象深刻的几次生产环境事故,均也来自于Airflow使用不当导致。
首先跨DAG依赖,可能会发生乐观锁问题。比如A和B内的task相互依赖,就有可能发生一直相互等待。
其次是较为常发生的Airflow任务一直hangon,task没有报错也没有执行状态,或者干脆一直执行,这种情况最快的处理方式就是手动杀死具体任务ID。更本质原因是Worker在等待资源或者干脆是Scheduler方面的问题,需要调优增加并发度等。
回头来看,调度本质解决的是资源编排问题。 针对资源问题本身,需要具体下药,Spark任务就走Spark的调优策略,数据的问题就按数据库的处理方式反思解决。 调度系统本质是一个整体资源管理器。
最后
截止2020年5月前,我们每日调度任务已经有几百个task。这些task相互关联依赖,在数据层面也存在耦合。 依赖调度系统,才精准的实现了数据资源的管控。
至于我那该死的睡眠,终于可以把定时闹铃先取消了,但是夜间调度任务报错后,还是依赖Airflow的报警机制给我们运维人员打电话和发钉钉。 致命错误还是需要人为介入处理比较快捷。 但是打电话还是有问题,天大的巧合发生过:夜间家里断网,住的小区偶尔夜间就没有了手机信号,导致错过一个报警。
我是一个纯粹的数据研发工程师吗?还是不确定。 我有了完整的睡眠了吗?依然没有。
那到底有啥进步?技术升级? 不不不,我觉得唯一的进步就是应对错误更从容了。
最大的反思是什么? 一切的开始是数据搬运问题。到最后成了一个调度系统。 工作中需要培养由小见大的能力,具体说来就是要在调研阶段极度复杂化看待问题,最后再抽丝剥茧回归问题本身。 作为一个数据工程师,是和信息系统完全耦合的职业状态,不会有完全的生活边界。 认真工作没有错,将工作视为全部,就是对待生活不认真,对待生活不认真,对待问题又怎么能认真呢? 失眠算什么,职业生涯赌进去才是最大的错。
我走错了很多路,现在要咬牙扳回来。