对于`CMeKG`中文医学知识图谱的技术调研
【目的】本次调研出发点是了解一个对外开放服务的知识图谱服务中包含的功能和模式,期望可以模拟一个类似服务。【方法】以“中文医学知识图谱”(下文使用CMeKG代替)为案例,罗列分析了伺服的功能模块,通过源码分析和API测试对该服务的技术栈进行了推测。【结果】最终罗列出可能会用到的技术栈,并给出一个最简原型仿制方案。【局限】相较于前端实现,对于后端服务中的知识图谱构建了解有限,只能模拟一个类似的通用知识图谱服务架构去仿制。【结论】基于开源工具库可以复现前端技术实现,对于后端中特定领域的知识图谱构建工作只能模拟部分数据服务能力。
1. 站点简述
官方介绍 CMeKG(Chinese Medical Knowledge Graph)是利用自然语言处理与文本挖掘技术,基于大规模医学文本数据,以人机结合的方式研发的中文医学知识图谱。作为一个面向领域的知识图谱服务,背后组成有:
- 自然语言处理与文本挖掘技术
- 基于大规模医学文本数据(反推有数据源支持)
- 人机结合的方式 (反推有医学领域专员支持完成实体对齐工作,同时该平台对外暴露了未开放的数据标注平台页面)
CMeKG采集和加工了多源的高质量的医学数据,具备成为准确完整的知识图谱的基础。不过由CMeKG产生的具体应用案例应用“医学知识文问答”,作为一个问答类应用似乎尚未开发完成,除给出的样例问题外,其余问题返回答案结果从正确性和精确度来讲都不符合预期。
客观来讲医学领域知识点繁杂,相同的疾病和药物可能在不同场景下就具备了不同的关系和属性。针对实体重复问题,CMeKG的优点之一是,在其医学知识基础集之上,进行了实体的对齐。比如,当使用者尝试搜索”面瘫“关键的时候,系统返回的结果是”面神经麻痹“。
为了调研具备参考样本,尝试搜索同类型服务比较CMeKG,发现还有平安智慧医疗推出的中文医疗知识图谱,不过没有找到直接服务入口或应用。由此反推面向领域的知识图谱开放性也存在局限。
2. 数据可视化
2.1 环形关系图
目前最新版本号CMeKG2.0,平台首页展示的环形菜单是一张疾病关系图,该图是基于JavaScript实现的ECharts可视化库进行可视化展现:
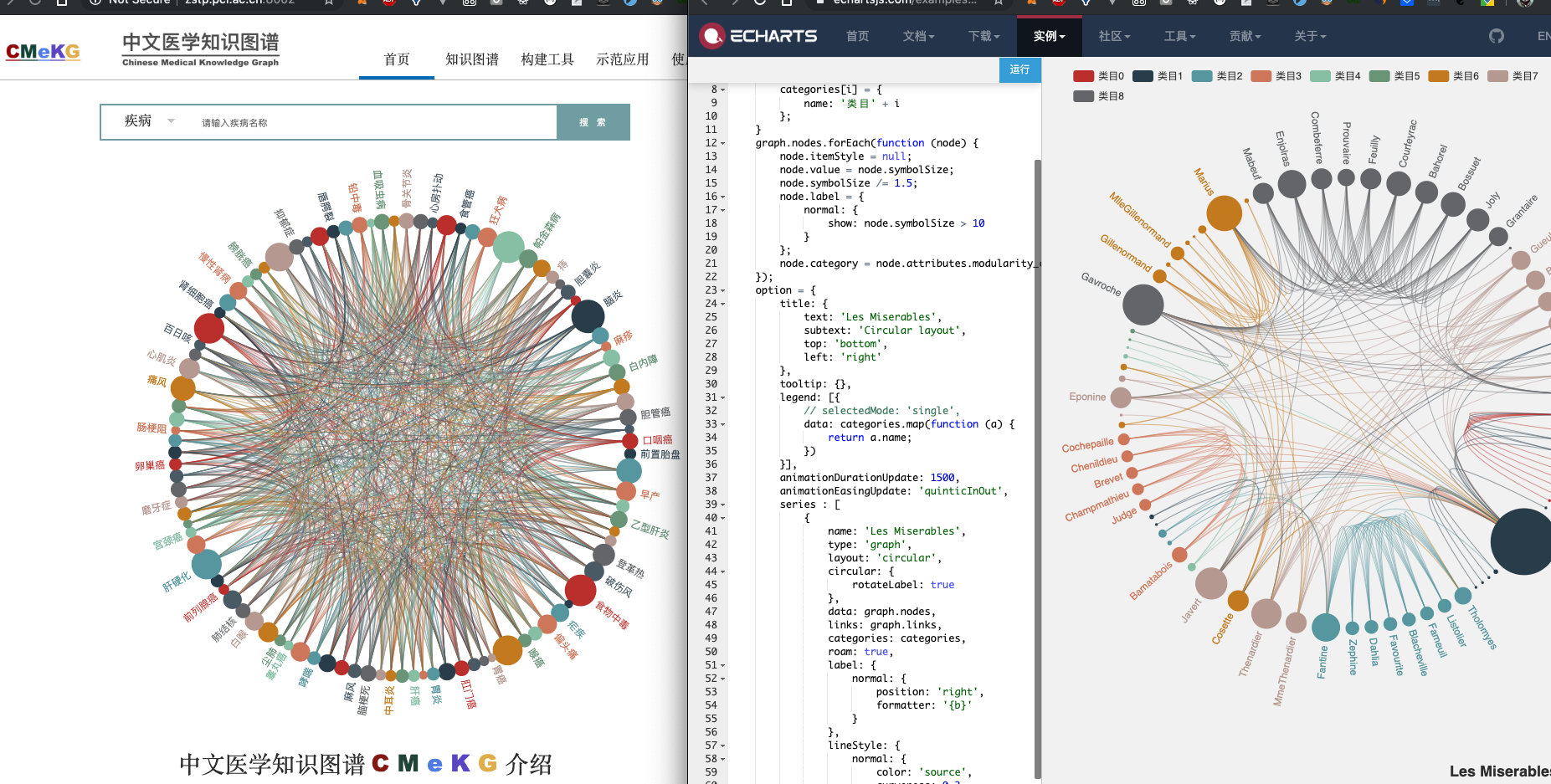
调查后发现是用ECharts的官方样例Les Miserables,可视化部分源码与官方样例基本一致。
前端调用GET API /circle_menu返回JSON结构的数据集交给ECharts渲染成为环形菜单使用。
2.2 力感关系图
单击环形菜单实体,就会跳转到基于该实体为对象的”知识图谱“功能页,页面内主要分两个功能模块,分别是左侧的树状图(官方文档称为多视图树状结构)和右侧的关系图。
左侧树状图分析源码可知是用了JQuery Ztree v3.5.37,基于此基础上自定义了样式。
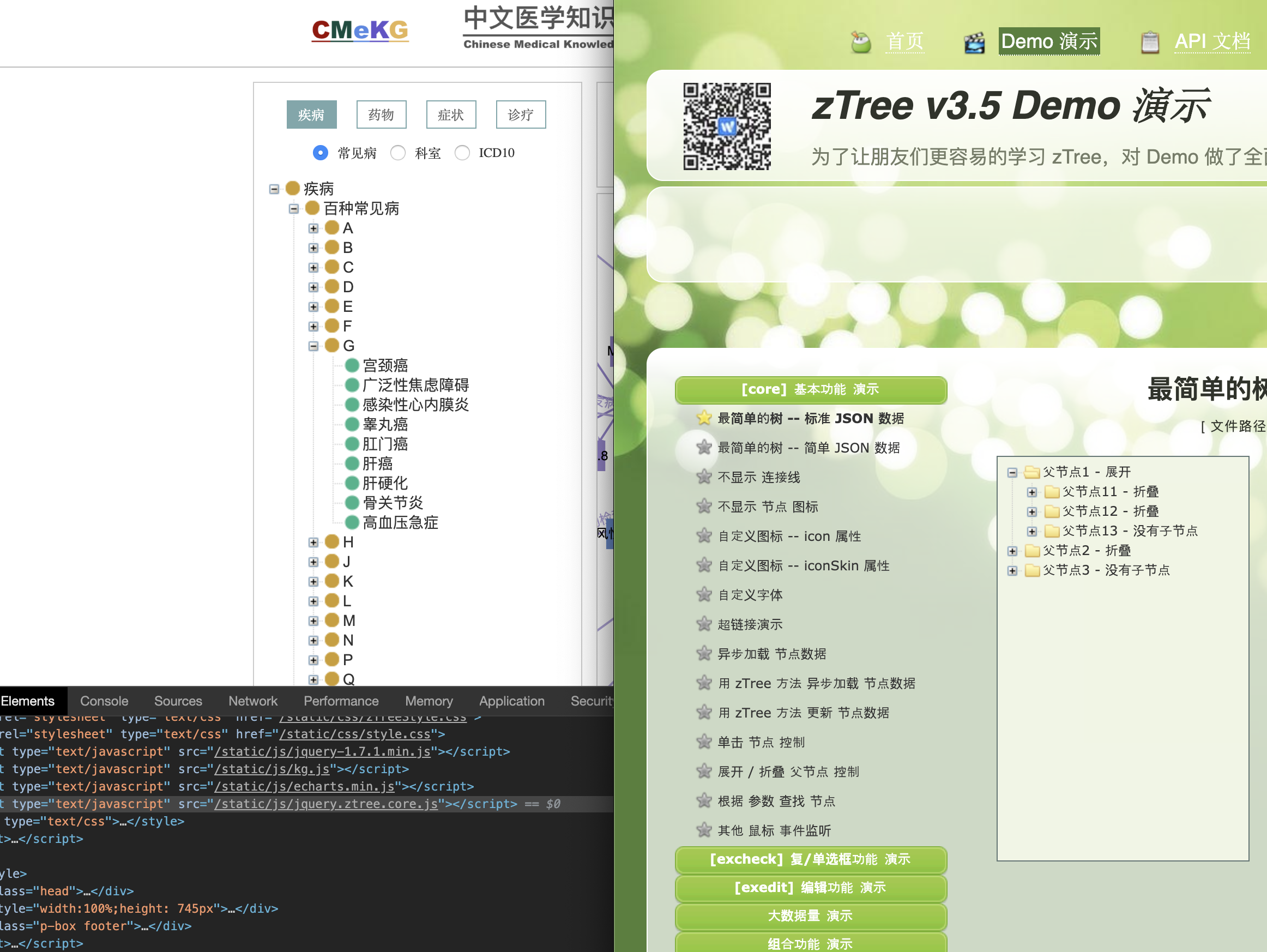
右侧的力感关系图依然采用ECharts实现,不过并未发现精确对应的样例名。下面罗列了几种类似实现:
| 力感关系图 - 不同类型实现列表 |
|---|
| 疾病药物关系图 |
| 力感拖动 |
| 物理挤压感拖动 |
| 关系方向指明 |
力感关系图页面源码有公开,没有混淆,可以调参数方式模仿。此外,描述schema结构的树图,可直接复用Echarts官方样例。
3. 数据层和模式层
网站第二大模块”构建工具“,其实是数据层和模式层的具体功能实现,包含四个部分:医学分词、关系抽取、描述框架和标注平台。
3.1 医学分词
医学分词模块为面向医学领域的自然语言处理。医学词条建设较为全面。试搜索一个非医学用语的时候,无法完成正确的分词。

分词从URL QUERY中提供待分词语句,然后由后端API返回分词结果。此处可以使用已有的开源分词库尝试模拟一个类似能力的API。
3.2 关系抽取
关系抽取模块针对于已经规范化标题和词条内容的百度百科依赖某些未知的规则进行知识抽取。
目前反推是通过已有关键字命中方式匹配内容然后返回。当尝试搜索同类型词条发现存在数据无法返回的情况,比如:
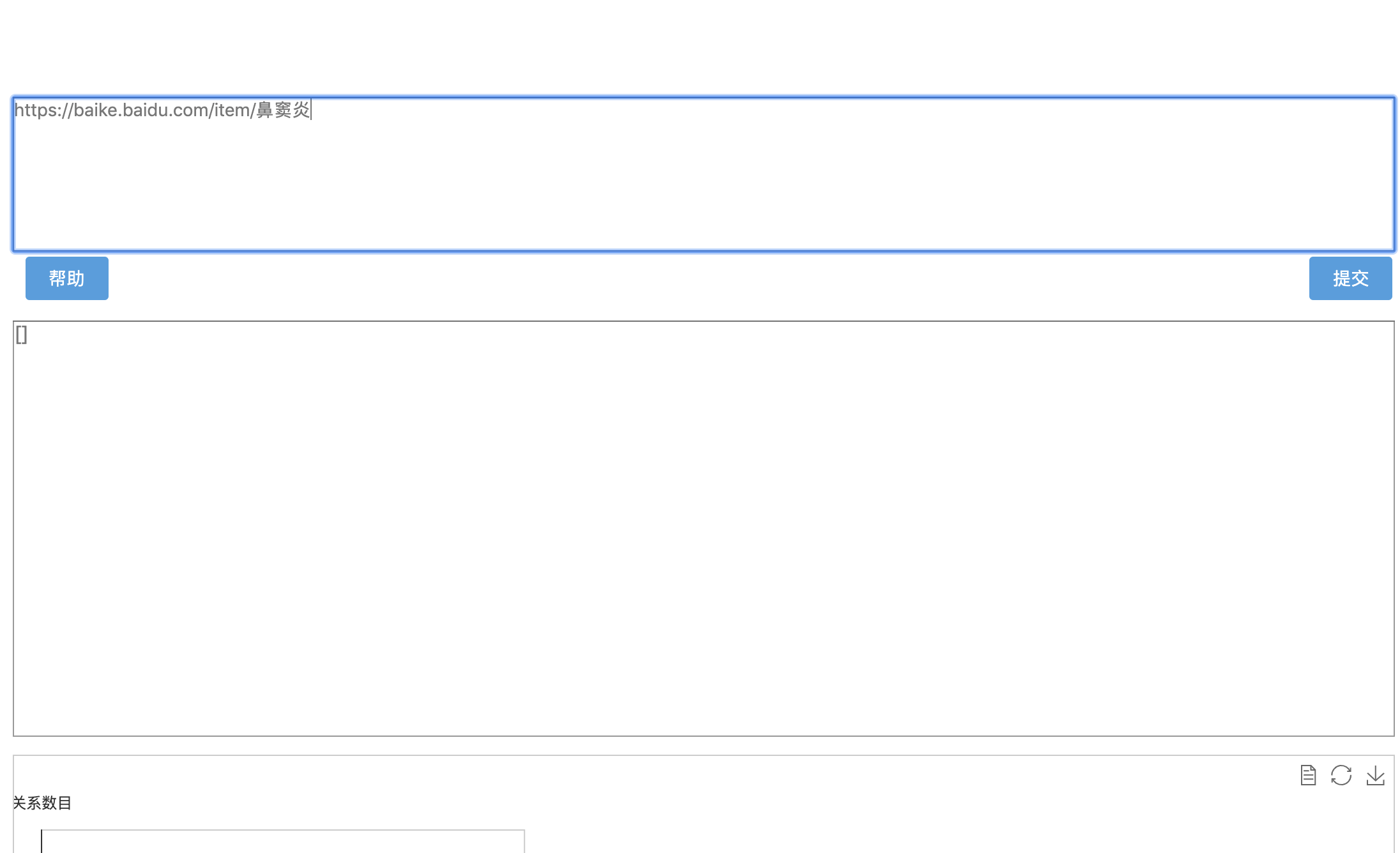
3.3 描述框架
描述框架为模式层的构建。可见CMeKG经过大规模的知识抽取后,构建出来一个针对医学领域较为通用的schema结构。该schema针对不同的知识元也有不同的扩展。
3.4. 标注平台
知识点之间的关联是经过了实体的对。对知识内容进行系统梳理的人工部分,CMeKG开发了专门的数据标注平台。目前尚未对外开放。
模拟架构
前后端分离,restful