简介Spark SQL中的窗口函数
本文是Databricks出品 Introducing Window Functions in Spark SQL by Yin Huai and Michael Armbrust的中文版本译文。原文发表于2015年。翻译措辞不太准确,仅限于对窗口函数了解食用。
在本文中将介绍Apache Spark新引入的窗口函数(window function)功能。窗口函数就是允许用户使用Spark SQL计算形如输入多行记录的排序,或求给定多行记录中某范围均值的功能。这一功能显著的提高了Spark SQL和DataFrame API功能的表达性。本文将先介绍窗口函数的基本概念,然后讨论如何在Spark SQL和Spark’s DataFrame API中使用这一功能。
1. 什么是窗口函数
在Apache 1.4以前,Spark SQL有两大类函数用于做单行计算结果的返回。其一是内置函数(Built-in functions)或用户自定义函数(UDF)用于返回单值。比如substr或round函数,每行记录中输入一个值进去,然后经过计算返回新值。单行进,单行出。其二是聚合函数,比如sum或max,输入的每一组记录经过聚合计算后返回一个单值。多行进,单行出。
尽管上述两种计算方式已经满足绝大部分需求场景,但是仍然有些操作无法单纯的通过上述函数的功能去实现。特别是无法实现既能对多行数据分组,又能基于分组维度之下再进行单值返回的计算。这种计算方式上的局限,让多维数据计算处理难去实现。比如在多行数据下逐行滑动范围然后求均值、计算累积值,或在计算“当前行”时访问到“之前行”的内容。万幸的是,Spark SQL的窗口函数功能填补了这一空白。
窗口函数的核心功能简言之就是:在进行计算时产生的多行记录组合成一个类表的集合或暂称为“数据框”,窗口函数计算该“数据框”后返回一个单行的值。计算时产生的每行记录会归到一个“数据框”,在其“框”内计算。这一特性强于其它函数的地方就是在应付多维数据处理过程中,使用窗口函数可以让逻辑更为简洁。且先看两个例子:
假设有一张productRevenue表,有商品、品类、价格三个字段,结构如下:
#cat /tmp/productRevenue.csv
product,category,revenue
Thin,Cell phone,6000
Normal,Tablet,1500
Mini,Tablet,5500
Ultra thin,Cell phone,5000
Very thin,Cell phone,6000
Big,Tablet,2500
Bendable,Cell phone,3000
Foldable,Cell phone,3000
Pro,Tablet,4500
Pro2,Tablet,6500
drop table if exists tmp.productRevenue;
CREATE TABLE IF NOT EXISTS tmp.productRevenue (
product string,
catetory string,
revenue INT
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
LINES TERMINATED BY '\n'
STORED AS TEXTFILE
tblproperties ("skip.header.line.count"="1");
LOAD DATA LOCAL INPATH '/tmp/productRevenue.csv' OVERWRITE INTO TABLE tmp.productRevenue;
select * from tmp.productRevenue;
基于上表的内容,我们尝试回答一下以下两个问题:
- 每个品类下,“销售最佳”和“销售第二”的商品是什么?
- “每个产品的单品价格”和“该产品在同品类下销售最佳的商品价格”之间的差值是多少?
针对第一个问题,我们需要做一个在品类维度下以价格为序的查询,并且从排序中找出销售头一头二的商品。下面的sql查询就是用到了滑动窗口函数dense_rank(后面将介绍这种滑动窗口的语法是什么意思)。
SELECT
product,
category,
revenue
FROM (
SELECT
product,
category,
revenue,
dense_rank() OVER (PARTITION BY category ORDER BY revenue DESC) as rank
FROM productRevenue) tmp
WHERE
rank <= 2;
查询执行结果如下所示。在没有窗口函数情况下,这个查询就很难用SQL方式表达了,更别提想用一行SQL去实现该需求。以往底层的查询引擎很难去高效的解析这种查询。
Product category revenue
Thin Cell phone 6000
Very thin Cell phone 6000
Ultra thin Cell phone 5000
Pro2 Tablet 6500
Mini Tablet 5500
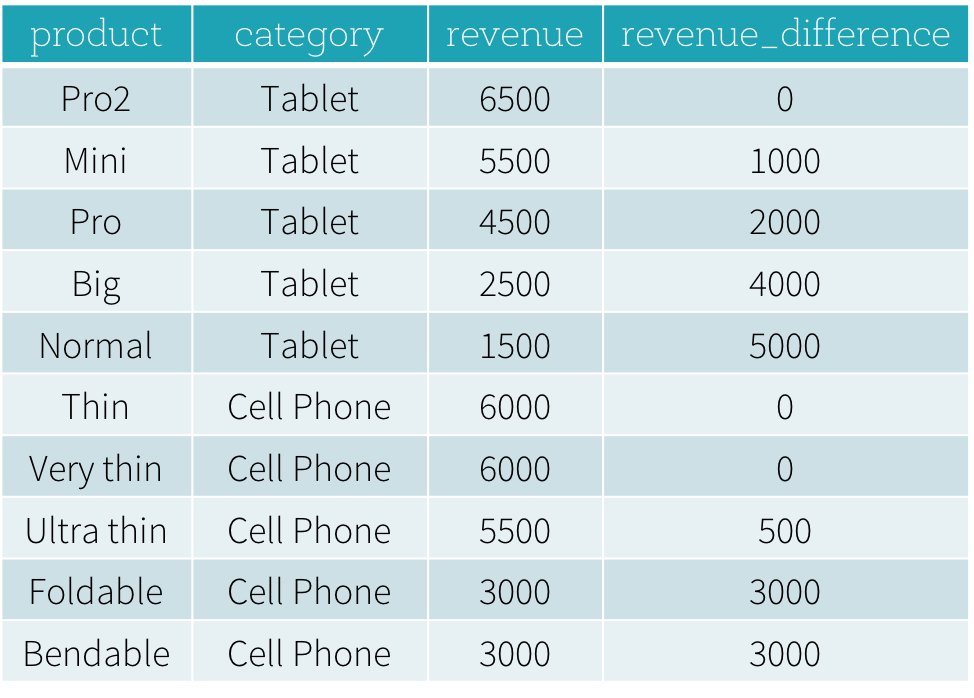
针对第二个问题,我们需要找出同品类下售价最高的产品,暂且称为商品A,然后用商品A的价格减去同品类下的各个商品的价格得出它们之间的价格差异。下面是用Python DataFrame的方式去实现这个需求:
import sys
from pyspark.sql.window import Window
import pyspark.sql.functions as func
windowSpec = \
Window
.partitionBy(df['category']) \
.orderBy(df['revenue'].desc()) \
.rangeBetween(-sys.maxsize, sys.maxsize)
dataFrame = sqlContext.table("productRevenue")
revenue_difference = \
(func.max(dataFrame['revenue']).over(windowSpec) - dataFrame['revenue'])
dataFrame.select(
dataFrame['product'],
dataFrame['category'],
dataFrame['revenue'],
revenue_difference.alias("revenue_difference"))
这段Python脚本的计算结果如下所示。在没有窗口函数助力情况下,我们得先找出各类产品中售价最高的产品价格,然后用得出的这组数据关联到原表中的价格字段做减法计算得出价格差。得出价格差后,再与原表关联得出最终结果。
2. 如何使用窗口函数
Spark SQL已支持三类窗口函数:排序函数,分析函数,和聚合函数。排序函数和分析函数有哪些已经总结在下表中。对于聚合函数,你可以把过去已常用的聚合函数(sum,avg)拿做窗口函数去用。
| SQL | DataFrame API | |
| Ranking functions | rank | rank |
| dense_rank | denseRank | |
| percent_rank | percentRank | |
| ntile | ntile | |
| row_number | rowNumber | |
| Analytic functions | cume_dist | cumeDist |
| first_value | firstValue | |
| last_value | lastValue | |
| lag | lag | |
| lead | lead |
想用窗口函数的话,你就用下面的方式去标记,代表想“开窗”:
- SQL语句中,在想执行开窗的函数的后面加一个 OVER 子句,比如
avg(revenue) OVER (...) - 同理,DataFrame API中,在想执行开窗的语句后也是加一个 over 方法,比如
rank().over(...)
当一个函数被标记成想“开窗”后,下一步就是定义一下针对这个窗口要做啥里面放点啥,这里暂且称为”窗口定义“。所谓”窗口定义“就是要将输入的各行数据生成前文所提到的“数据框”。一个“窗口定义”要包含三个部分去声明:
- 分区字段的定义:控制哪些行记录要被分到同一分区。此外,用户可能希望在排序和计算”数据框”之前,将category列相同的记录都收集到同台机器上去计算。如果不去定义分区字段,那么所有的数据必须集中在同一台机器上就算才行。
- 排序字段的定义:控制分区后数据行的排序方式,让分区内的数据都是有序的。并且还给分区内的每行记录标记上其所在位置的序号。
- 框选范围定义:根据当前行划定一个范围,相对于当前行的所有数据行归为一个”数据框”内。比如说,“从当前行之前的3行,直到当前行”,这就形容了一个包含了当前行并且相对往前推三行的数据行,共有四行记录,都纳入了一个框内。
在SQL中,PARTITION BY和ORDER BY关键字是分别用于分区字段定义的表达式和排序字段定义的表达式。SQL语法如下所示:
OVER (PARTITION BY ... ORDER BY ...)
在DataFrame API中,提供了工具函数去做“窗口定义”。在下面的Python示例中,示范了分区表达式和排序表达式的用法:
from pyspark.sql.window import Window
windowSpec = \
Window \
.partitionBy(...) \
.orderBy(...)
除了排序和分区外,用户还需要定义”数据框”的开始和结束的边界,以及“数据框”的类型,这是“数据框”的三大组成部分。
这个“数据框”的框选范围声明方式有5种,分别是向前无界UNBOUNDED PRECEDING,向后无界UNBOUNDED FOLLOWING,当前行CURRENT ROW,前界定值<value> PRECEDING以及后界定值<value> FOLLOWING。其中的向前无界和向后无界也就是说分区的第一行和分区的末尾行。其余三种边界都是属于基于相对值设定边界。它们针对指定的当前行为准,相对这个当前行前或后偏移取值。同时,还要声明一个”数据框”的计算类型。一般“数据框”有基于行ROW frame和基于范围Range frame两种计算类型。
ROW frame
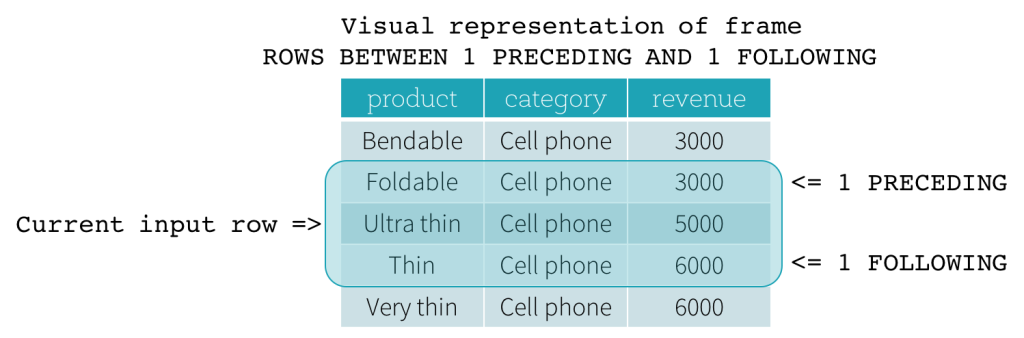
基于行的“数据框”计算是取实际偏移量,以当前行为基准行前后划定范围。这意味着框选范围的当前行,前界定值,后界定值都是按照实际偏移多少行后划定取值范围。如果当前行被指定为边界,那就代表着取当前行为界值。前界定值和后界定值意思就是,基于当前行往前取多少行,往后取多少行。下图示例了向前取1行为始,向后取1行为终的情况(SQL表达式ROWS BETWEEN 1 PRECEDING AND 1 FOLLOWING)。
RANGE frame
基于范围的“数据框”则是对当前行做了一个逻辑计算得出前后偏移量,然后划定了一个逻辑意义(经过一层计算得出)的取值范围,SQL语法上类似上面所述的基于行的“数据框”取值。
逻辑偏移量是在一个已经排序的“数据框”下计算得出的,以当前输入行为基准值,完成逻辑加或减的计算得出最终的偏移量,以这个得出的前后偏移量,作为取值范围。如此说来,当想用基于范围的”数据框”的时候,只能允许使用一个排序表达式对数据集排序,否则多次混叠排序后就影响了数据集的第一序,间接影响了逻辑偏移范围的划定。另外,对于基于范围的“数据框”,直到整个数据集合的边界范围划分完为止,就有可能会计算出具有同一取值范围的”数据框”,其计算结果相同,就作为一个结果返回。
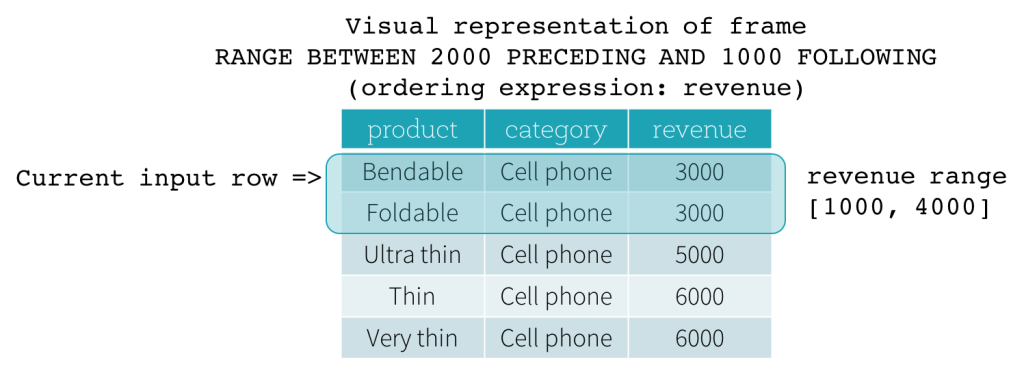
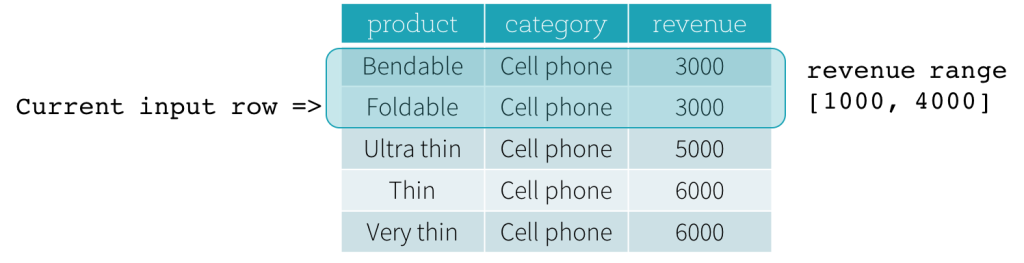
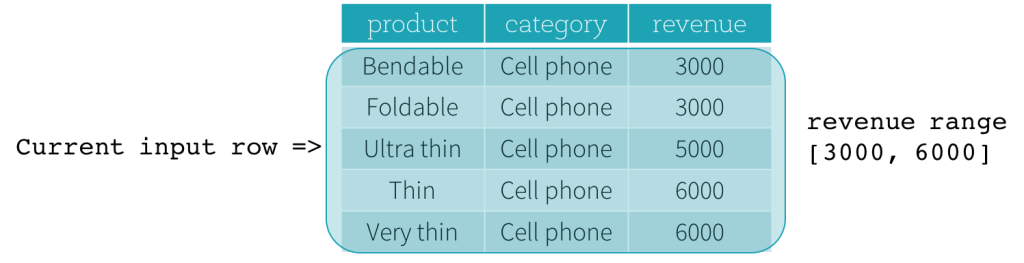
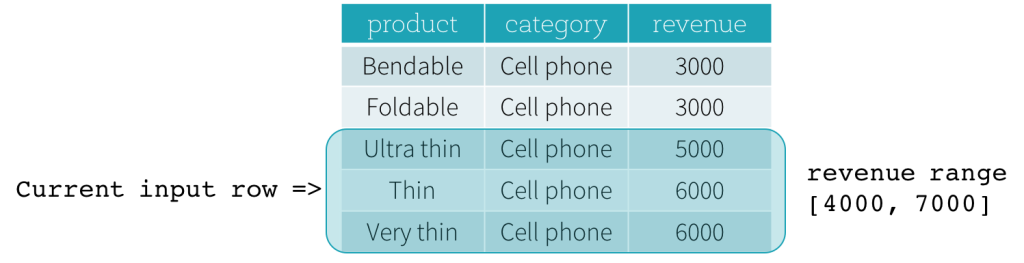
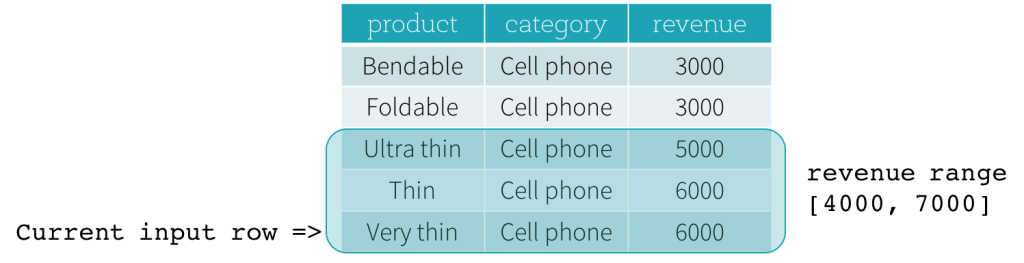
现在,我们一起看一个示例。在下面例子中,排序表达式作用于revenue字段,前定界是2000 PRECEDING,后定界是1000 FOLLOWING(用SQL表达式描述这个数据框就是RANGE BETWEEN 2000 PRECEDING AND 1000 FOLLOWING)。下面5张图描述了当前行不断更新过程中,整个“数据框”是如何随着改变的。基本上,对于每一个输入行的revenue值都做一次取范围的计算:[ 当前行的revenue值 - 2000, 当前行的revenue值 + 1000 ],从而得出一个取值范围。用得出的取值范围作为当前行的前后界定范围就得出了想要的结果。
比如第三张图中,当前行revenue值为5000,前后界定范围就是[5000 - 2000, 5000 + 1000] = [3000, 6000],那就是所有 3000 <= revenue <= 6000的范围的记录构成想要的基于范围的”数据框”。
总结一下,用户可以通过如下的SQL语法去定义个要计算的窗口,完成一次“开窗”:
OVER (PARTITION BY ... ORDER BY ... frame_type BETWEEN start AND end)
这里的frame_type可以写ROWS(用于基于行的”数据框”)或 RANGE(基于范围的“数据框”)。
start可以是UNBOUNDED PRECEDING,CURRENT ROW,<value> PRECEDING和 `
end可以是UNBOUNDED PRECEDING, CURRENT ROW ,<value> PRECEDING和 <value> FOLLOWING 。
用Python的DataFrame API的话,用户可以用如下方式完成一次“开窗定义”:
from pyspark.sql.window import Window
# Defines partitioning specification and ordering specification.
windowSpec = \
Window \
.partitionBy(...) \
.orderBy(...)
# Defines a Window Specification with a ROW frame.
windowSpec.rowsBetween(start, end)
# Defines a Window Specification with a RANGE frame.
windowSpec.rangeBetween(start, end)
3. 展望未来
后续优化将为Date和Timestamp类型数据添加interval功能的支持,方便做时序分析。
在开窗功能上,将支持用户自定义的聚合功能以应付更高级的数据分析需求。