基于Keepalive + MySQL主从实现高可用架构
数据平台HDP或CDH一般使用MySQL做元数据信息存储,尤其重要的Hive元数据信息更是绝对不能丢。 这就牵扯到要做元信息库的高可用。
简单场景的mysql高可用,一般是两个思路:
- keepalive + mysql主从
- keepalive + mysql双主
这里还得废话两句主从和双主区别在哪里。先简单了解一下:
MySQL主从架构:
主从架构是传统MySQL集群搭配方法,
这种架构设计就是假设单点服务只负责读或写一个功能。
主节点只负责写,然后读就只用从节点。
各司其职,从而降低同时读写导致产生性能问题。
这事情的另一个说法叫读写分离。
既然做读写分离,那肯定就也会遇到读写分类带来的麻烦,最常见的一种问题就是主节点完成的一系列事务操作再扔到从节点上执行时候就失败了,数据一致性就没得谈。 然后其实依然也存在单点问题,比如大量写的操作只能放主节点上执行,对主节点的性能很是考验,而且还不能水平扩展。 在手动做故障迁移的时候,还需要进一步判断主从两个节点数据是否一致,选择最新数据的为准。
MySQL双主架构: 其实双主架构是主从架构演化而来的。 这种架构就是假设你有多个主节点同时需要读写以应付大量请求。 但是需要注意的是,在这样情况下,节点之间数据同步是异步的。
双主架构说白了最大的好处就是可以水平扩展机器了,请求量大了后直接扩展几台机器来吃压就行。 其中一台主节点万一出了问题,可以直接将其下线,读写请求平滑的迁移到其它机器。
双主架构的缺陷也对应而生,在节点之间数据异步同步期间,可能有些事务操作就失效了,多节点直接不能保证最终一致。 相应在搞数据备份的时候,就不能确定到底是不是最新数据,不同节点数据可能不一样嘛。
在数据平台应用的场景下,推荐1号主从方案。 具体原因是我们踩过坑,吃了一憋。 由于一次意外断电情况,导致双主数据库发生脑裂问题,数据不一致。 两个节点数据来回漂移,都产生了最新数据,苦了工程师去两头修,最后逐条比对然后恢复数据。 像是数据平台这种对实时性要求不高的场景,还不如直接主从架构,在意外发生的时候,手动判断为主,优先使用主节点数据,不要keepalive自己漂移。
但是!MySQL高可用玩法不只限于如此,水深玩法多,比如还有更可靠的MySQL Cluster模式。
我看了一下午,越扒水越深。
详见Pros and Cons of MySQL Replication Types。
实现效果
依据本文引导,最终实现的效果如图所示:
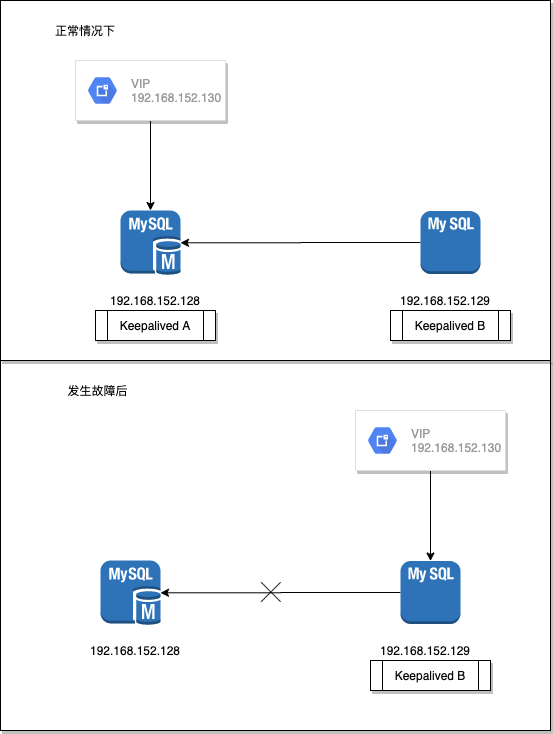
- 默认情况下主节点对外服务,从节点只负责数据备份。
- 发生意外后,VIP漂移到从节点。从节点只提供只读服务。
- 运维手动恢复主节点后,VIP回到主节点。
真实的场景可能是这样的,主节点机器由于重启或断电导致MySQL暂时下线。 从节点立马上线,但是只能提供只读服务。 集群的数据停滞在这个时间点,不再变化。 整个数据集群虽然依然可用,但就是不能往里面写数据了,部分数仓或分析人员的代码如果有写的行为会报错进入retry。 运维收到钉钉报警,立马介入处理,让主节点再次上线。 手工操作让从节点的VIP再漂移回主节点。 集群恢复正常。
物料准备
操作系统:
cat /etc/redhat-release
CentOS Linux release 7.3.1611 (Core)
SELinux Config设置为DISABLED
systemctl stop firewalld.service
systemctl disable firewalld.service
yum -y install openssh-server openssh-clients
vim /etc/selinux/config #设置为disabled
安全设置生效需要重启。
MySQL的下载和安装:
wget http://repo.mysql.com/mysql-community-release-el7-5.noarch.rpm
sudo rpm -ivh mysql-community-release-el7-5.noarch.rpm
sudo yum -y install mysql-server
(数据库版本号最好和生产环境完全对应,MySQL Archives整理的非常规范。 )
高可用集群的服务IP规划:
| Name | IP | Desc |
|---|---|---|
| VIP | 192.168.152.130 | 虚拟IP |
| master | 192.168.152.128 | 主IP |
| slave | 192.168.152.129 | 从IP |
安装keepalived
yum install -y keepalived
keepalived -v
Keepalived v1.2.13 (11/05,2016)
文档中涉及的全部配置文件见github项目keepalived_mysql_master_slave。 保证版本差不多的前提下,应该都通用。
MySQL主从复制环境
首先是所有MySQL节点账户和权限的初始化操作,这里重点关注设置好正确的用户密码和开放权限到所有机器可以访问:
/usr/bin/mysql_secure_installation
grant all privileges on *.* to 'root'@'%' identified by '123456';
flush privileges;
一般在搭建数据平台集群的时候都是给一个具备super能力的root用户直接刚。
此处就不过多纠结权属设计问题了。
主从节点MySQL配置/etc/my.cnf,注意有不一样的地方,my.cnf文件可以直接从上面提到的github项目提取粘贴到对应位置:
# 主节点修改
# cat /etc/my.cnf
[mysqld]
datadir=/var/lib/mysql
socket=/var/lib/mysql/mysql.sock
# Disabling symbolic-links is recommended to prevent assorted security risks
symbolic-links=0
# Recommended in standard MySQL setup
sql_mode=NO_ENGINE_SUBSTITUTION,STRICT_TRANS_TABLES
log_slave_updates
log-bin = mysql-bin
server-id = 1
slave-skip-errors = all
auto_increment_increment = 2
auto_increment_offset = 1
binlog_format = mixed
character_set_server = utf8
[mysqld_safe]
log-error=/var/log/mysqld.log
pid-file=/var/run/mysqld/mysqld.pid
从节点MySQL配置中的read_only可以删掉:
# 从节点修改
# cat /etc/my.cnf
[mysqld]
datadir=/var/lib/mysql
socket=/var/lib/mysql/mysql.sock
read_only = 1
symbolic-links=0
sql_mode=NO_ENGINE_SUBSTITUTION,STRICT_TRANS_TABLES
log_slave_updates
log-bin = mysql-bin
server-id = 2
slave-skip-errors = all
auto_increment_increment = 2
auto_increment_offset = 2
binlog_format=mixed
character_set_server=utf8
[mysqld_safe]
log-error=/var/log/mysqld.log
pid-file=/var/run/mysqld/mysqld.pid
主从修改后均先重启测试是否正常启动,各自请求对端mysql看能否正确访问:
systemctl enable mysql.service
systemctl restart mysql.service
mysql -u root -p -h <换成主或从IP地址> -P 3306
在主从MySQL下创建同步账户:
CREATE USER 'replica'@'%' IDENTIFIED BY '123456';
GRANT REPLICATION SLAVE ON *.* TO 'replica'@'%';
或
grant replication slave on *.* to 'replica'@'%' identified by '123456';
在主MySQL shell里执行获得同步状态,配置从节点时候会用到:
mysql> SHOW MASTER STATUS\G
*************************** 1. row ***************************
File: mysql-bin.000004
Position: 705
Binlog_Do_DB:
Binlog_Ignore_DB:
Executed_Gtid_Set:
1 row in set (0.00 sec)
接下来就是在MySQL从节点做同步配置。
需要用上主节点的File和Position信息:
--! mysql shell内执行停止slave操作防呆
STOP SLAVE;
CHANGE MASTER TO MASTER_HOST='192.168.152.128', MASTER_USER='replica', MASTER_PASSWORD='123456', MASTER_LOG_FILE='mysql-bin.000004', MASTER_LOG_POS=705;
START SLAVE;
从节点查看同步状态,看到running都是yes算正常:
mysql> show slave status\G
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: 192.168.152.128
Master_User: replica
Master_Port: 3306
Connect_Retry: 60
Master_Log_File: mysql-bin.000004
Read_Master_Log_Pos: 705
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
......
截止这一步,主从同步配置已经完成,测试方法就是在主MySQL建个库,然后看从库是否出现同名库。
主从配置流程讲得比较清楚简明的文章可以参考How to Setup MySQL Master Slave Replication on Ubuntu 18.04。
Keepalive配置
主从MySQL搞定后,就开始折腾keepalive,keepalive在这里负责的功能就是监听着mysql状态,发生不同状态调用不同的脚本。
这些脚本里面就是一堆设置mysql参数的代码行。
通过不同参数执行,让mysql进入到不可写或开始同步的状态。
主从都需要安装keepalived服务:
keepalived -v #Keepalived v1.3.5 (03/19,2017), git commit v1.3.5-6-g6fa32f2
在keepalive中配置了VIP(配置项virtual_ipaddress)。需要注意的地方是:
- 修改
interface <网卡名>,比如下面配置中的ens33是我的网卡名,你需要改掉 - 主从修改
unicast_src_ip和unicast_peer成对应的IP virtual_ipaddress里同样需要修改网卡名
主节点keepalive配置/etc/keepalived/keepalived.conf:
# cat /etc/keepalived/keepalived.conf
global_defs {
router_id MySQL-HA
}
vrrp_script check_run {
script "/usr/local/bin/mysql_check.sh"
interval 10
weight 2
}
vrrp_instance VI_1 {
state BACKUP
interface ens33
virtual_router_id 51
unicast_src_ip 192.168.152.128
unicast_peer {
192.168.152.129
}
priority 150
advert_int 1
nopreempt
authentication {
auth_type PASS
auth_pass 1111
}
track_script {
check_run
}
notify_master /usr/local/bin/master.sh
notify_backup /usr/local/bin/backup.sh
notify_stop /usr/local/bin/stop.sh
virtual_ipaddress {
192.168.152.130/24 dev ens33
}
}
从节点keepalive配置/etc/keepalived/keepalived.conf:
# cat /etc/keepalived/keepalived.conf
global_defs {
router_id MySQL-HA
}
vrrp_script check_run {
script "/usr/local/bin/mysql_check.sh"
interval 120
weight 2
}
vrrp_instance VI_1 {
state BACKUP
interface ens33
virtual_router_id 51
unicast_src_ip 192.168.152.129
unicast_peer {
192.168.152.128
}
priority 100
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
track_script {
check_run
}
notify_master /usr/local/bin/master.sh
notify_backup /usr/local/bin/backup.sh
notify_stop /usr/local/bin/stop.sh
virtual_ipaddress {
192.168.152.130/24 dev ens33
}
}
配置文件搞定后,还需要将配置中的脚本也都一一放好。
Keepalive内脚本
在keepalive内用到4个脚本,全部放到/usr/local/bin/下:
| 脚本 | 功能 |
|---|---|
/usr/local/bin/mysql_check.sh |
mysql_check.sh是为了检查mysqld进程是否存活的脚本,当发现连接不上mysql,自动把keepalived进程干掉,让VIP进行漂移。 |
/usr/local/bin/master.sh |
主从master脚本不一样但是功能差不多,作用是状态改为master以后执行的脚本。首先判断复制是否有延迟,如果有延迟,等1分钟后,不论是否有延迟。都跳过,并停止复制。并且授权账号,记录binlog和pos点。 |
/usr/local/bin/stop.sh |
stop.sh 表示keepalived停止以后需要执行的脚本。更改密码,设置参数,检查是否还有写入操作,最后无论是否执行完毕,都退出。 |
/usr/local/bin/backup.sh |
backup.sh脚本的作用是状态改变为backup以后执行的脚本。 |
脚本原理参考的 Keepalived+MySQL实现高可用。
我修改后搬运到了,github项目keepalived_mysql_master_slave。
注意设置这一组脚本权限为764
chmod 764 ./*.sh
流程测试
首先确定已经启动主从的MySQL然后启动keepalived,注意有先后顺序:
systemctl restart mysql
sleep 5
systemctl restart keepalived
systemctl status mysql
systemctl status keepalived
如果都在running那说明没问题,至此主从MySQL和主从的keepalived就算全部设置完工。
主节点执行ip addr | grep 192 会看到主节点IP和VIP两个地址。
通过VIP访问到MySQL:
mysql -ureplica -p123456 -h 192.168.152.130
测试方法就是,强杀主节点的MySQL:
pkill -9 mysqld
杀死后VIP会“漂移”到从节点。主节点执行ip addr | grep 192 只能看到主节点IP。
mysql -ureplica -p123456 -h 192.168.152.130依然可以访问到数据库,但是已经不能执行insert操作。
这样就算是模拟了一次事故。
事故后恢复
在模拟事故后,就是如何恢复的问题。 假设运维人员经过抢修,主节点已经可以恢复服务。 首先就先后启动MySQL和keepalived:
systemctl restart mysql
sleep 5
systemctl restart keepalived
systemctl status mysql
systemctl status keepalived
此事主节点已经可以再次营业了,需要运维人员在从节点机器上完成一个手工操作:
systemctl restart keepalived
这个操作的含义就是模拟了从节点keepalive暂时挂掉,让VIP漂移回了主节点。
在做从节点数据无法写入测试的时候,不要用test或test_前缀的库。
至此,大功告成。
我在搞这个事情时候遇到一些理解上的问题,如感兴趣,且来围观: